Whenever you visit a page on the web, your computer uses the Hypertext Transfer Protocol (HTTP) to get that page from another computer somewhere on the Internet.

Let’s see how that happens
URL (Uniform Resource Locator)
When one want to browse the web, one can use many types of computers (like laptops, desktops, and phones), as long as the computer has a (any) browser application installed.
The user either types a Uniform Resource Locator (URL) in the browser (i.e http://example.com/) or follows a link from an already opened page
Notice something about that URL: it starts with http. That’s a signal to the browser that it needs to use HTTP to fetch the document for that URL.
DNS Search: Browser looks-up for IP
We typically type nice human-friendly URLs into browsers, like google.org and wikipedia.org. Those domain names map to IP addresses, the true location of the domain’s computers. That’s handled by the Domain Name System. The browser uses a DNS resolver to map the domain to an IP address. To know IP of an URL, one can try using CMD tool ping. So to know IP for www.google.com try following
ping www.google.com
// => PING www.google.com (142.250.195.164): 56 data bytes
So 142.250.195.164 is IP for google.com. Now if one tries putting 142.250.195.164 instead of google.com, it should again take us to google.com
HTTP request after DNS resolution
Once the browser identifies the IP address of the computer hosting the requested URL, it makes an HTTP request. An HTTP request can be as short as two lines of text.
GET /index.html HTTP/1.1
Host: www.example.com
The first word is the HTTP verb: GET. There are other verbs for other actions on the web, like submitting form data (POST). The next part specifies the path: /index.html. The host computer stores the content of the entire website, so the browser needs to be specific about which page to load. The final part of the first line specifies the protocol and the version of the protocol: “HTTP/1.1”.
The second line specifies the domain of the requested URL. That’s helpful in case a host computer stores the content for multiple websites.
HTTP response
Once the host computer receives the HTTP request, it sends back a response with both the content and metadata about it.
The HTTP response starts similarly to the request:
HTTP/1.1 200 OK
The response begins with the protocol and version, HTTP/1.1. The next number is the very important HTTP status code, and in this case, it’s 200. That code represents a successful retrieval of the document (“OK”).
If the server fails to retrieve the document, the status codes provide more information, like if the failure was due to user error or server error. For example, the most well known status code is 404 (File not found). That happens whenever you visit a path on a server that doesn’t correspond to any document. Since users have a habit of typing URLs incorrectly, 404s happen frequently, so websites often have fun 404 webpages.
The next part of an HTTP response are the headers. They give the browser additional details and help the browser to render the content. These two headers are common to most requests:
Content-Type: text/html; charset=UTF-8
Content-Length: 208
The content-type tells the browser what type of document it’s sending back. A common type on the web is “text/html”, as all webpages are HTML text files. Other types are possible, like images (“image/png”), videos (“video/mpeg”), script (“application/javascript”) and anything else you can load in your browser.
The content-length gives the length of the document in bytes, which helps the browser know how long a file will take to download.
Finally, the HTTP response writes out the actual document requested. This page is a simple HTML file and is rendered by browser’s rendering engine.
<!DOCTYPE html>
<html>
<head>
<title>Example Domain</title>
</head>
<body>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>
</body>
</html>
Rendering the response
The browser now has all the information it needs to render the document requested.
Many browsers include debugging tools that let you view HTTP requests and their responses as you browse the web. Let’s try it in Chrome.
First, we need to open the Chrome developer tools. One way to do that is to open the “View” menu, then select “Developer” → “Developer Tools”. Once that pops open, select the “Network” tab.
Next, type a URL in the browser bar, like “http://www.example.com/index.html”. An HTTP request shows up in the console, and the browser renders the page.
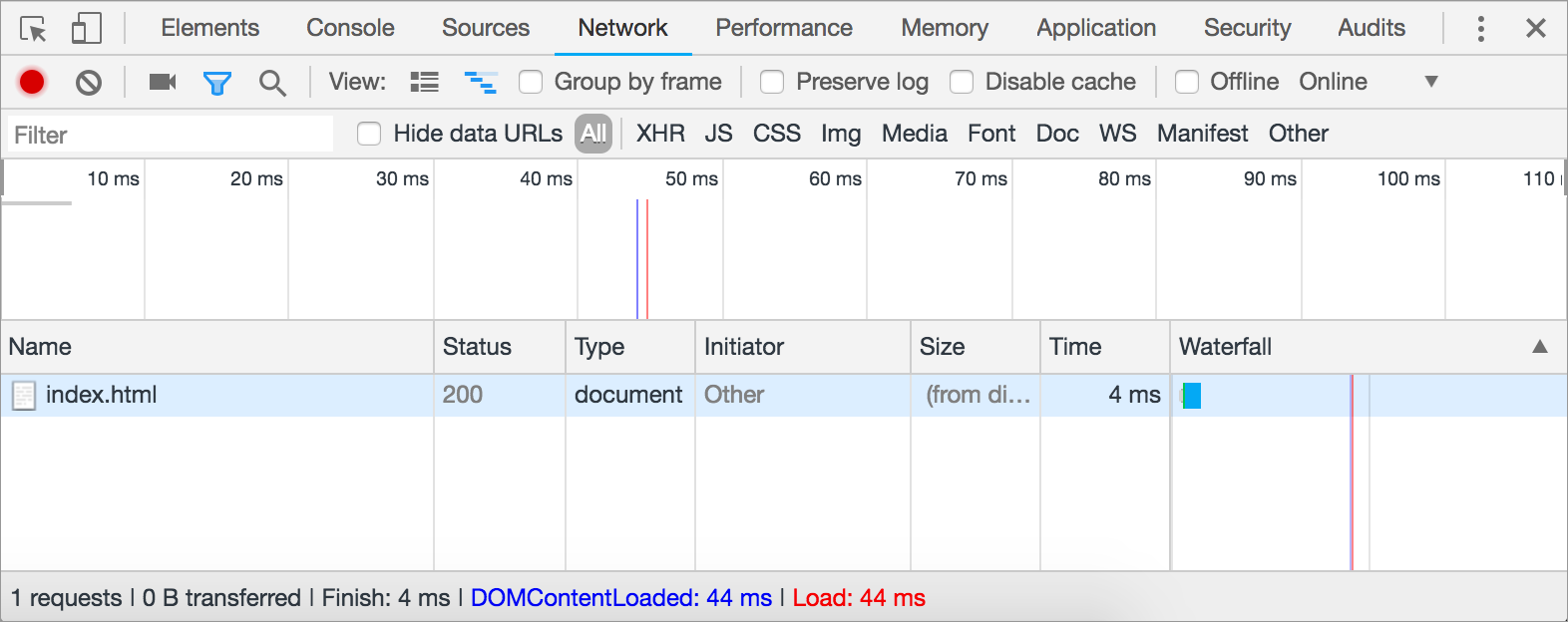
We can dig into that request to see the juicy details, if we want. Click “index.html” under the “Name” column”. A tabbed interface pops up and defaults to a “Headers” tab.
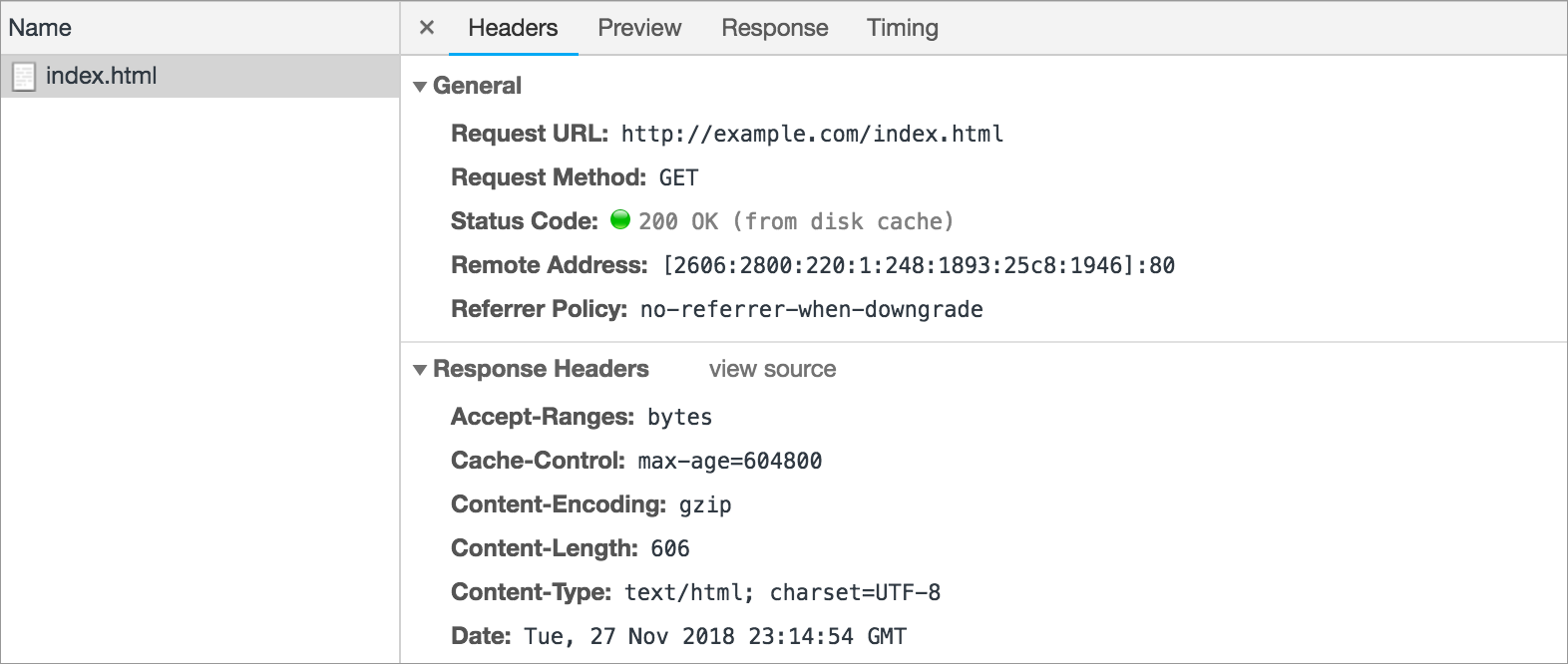
The “Response headers” includes headers discussed above, like “Content-Type” and “Content-Length”, plus lots of other interesting headers.
The actual HTML content of the response is another tab, “Response”.

Open up the “Network” tab and browse to more websites. How many HTTP requests does each website make? What types of content are in the responses? What surprises you the most?
There are many other protocols built on top of TCP/IP, like protocols for sending email (SMTP, POP, IMAP) and uploading files (FTP).
All of these protocols enable us to use the Internet to connect with other computers in useful ways, and to communicate and collaborate across wide distances.
About The Author
I am Pankaj Baagwan, a System Design Architect. A Computer Scientist by heart, process enthusiast, and open source author/contributor/writer. Advocates Karma. Love working with cutting edge, fascinating, open source technologies.
To consult Pankaj Bagwan on System Design, Cyber Security and Application Development, SEO and SMO, please reach out at me[at]bagwanpankaj[dot]com
For promotion/advertisement of your services and products on this blog, please reach out at me[at]bagwanpankaj[dot]com
Stay tuned <3. Signing off for RAAM